

This blog post is adapted from a presentation given by John Willis at nginx.conf in San Francisco in September 2015. You can watch the video of the presentation on YouTube.
Table of Contents
0:10 Introduction
Hi. I’m John Willis, Director of Ecosystem Development at Docker.
![John Willis have worked for 35 years in IT operations and is a core organizer of DevOpsDays [presentation by John Willis, Director of Ecosystem Development at Docker, at nginx.conf 2015]](https://cdn.wp.nginx.com/wp-content/uploads/2016/08/Willis-conf2015-slide2_bio.png)
You could say that I’m an IT operations junkie. Other than my wife and my kids, that’s really all I think about. Well, maybe sports on Saturdays.
I have 35 years of IT operations experience. I’ve worked at Exxon and Canonical. I had an amazing experience at Chef.
And the start‑up gods have been pretty good to me recently. I founded a company I sold to Dell called Enstratius. Most recently, I founded the company called Socketplane which is now part of Docker.
I am one of the original core organizers of DevOps. I was the only American at the original DevOpsDays in Ghent six years ago. I brought the first [DevOpsDays] conference here to the US. Along with a bunch of other people, I’ve been really a big part of that movement. And I’ve been doing the DevOpsCafe podcast for six years, where we interview all the leaders in the movement.
2:37 Immutable
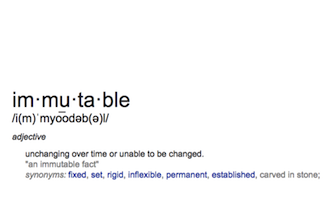
I’ve had people ask what immutable means, so let’s take a look at the dictionary definition.
![The dictionary definition of 'immutable' is "unchanging over time or unable to be changed" [presentation by John Willis, Director of Ecosystem Development at Docker, at nginx.conf 2015]](https://cdn.wp.nginx.com/wp-content/uploads/2016/08/Willis-conf2015-slide3_definition.png)
But even as we’re looking at this definition, I want to get it out of the way that in our industry, we’re not really using it in the exact, strict mathematical way. It’s probably better to think of it as a metaphor that describes how we want to do our infrastructure.
3:50 Immutable Infrastructure Myth
![Slide reads "Immutable Insfrastructure Myth" [presentation by John Willis, Director of Ecosystem Development at Docker, at nginx.conf 2015]](https://cdn.wp.nginx.com/wp-content/uploads/2016/08/Willis-conf2015-slide4_myth.png)
In a way I will agree with some of my friends from math or physics backgrounds that in IT, there is technically no such thing as a completely immutable (by the dictionary definition) infrastructure.
If we can get past that, we can start thinking about this model of how you might want to think about delivery, instead of people fighting on Twitter for 40 pages about why the term doesn’t make sense and why we should use some other term. This actually happens fairly regularly, no joke.
4:25 Order Matters
![The "Order Matters" principle, formulated by Steve Traugott, states that the lowest cost way to ensure identical behavior on two hosts is always to implement the same changes in the same order on both [presentation by John Willis, Director of Ecosystem Development at Docker, at nginx.conf 2015]](https://cdn.wp.nginx.com/wp-content/uploads/2016/08/Willis-conf2015-slide5_order-matters.png)
Let’s start with Why Order Matters, a paper written by Steve Traugott back in 2002. It’s very mathematical, but it makes a really good point about how order matters for configuration management.
If you read this paper, it almost screams Docker. He makes a very good argument for why, at scale, immutable infrastructure works. He proves the value of immutability.
5:33 Management Methods
![Three methods for managing infrastructure, in increasing order of desirability, are divergence, convergence, and congruence [presentation by John Willis, Director of Ecosystem Development at Docker, at nginx.conf 2015]](https://cdn.wp.nginx.com/wp-content/uploads/2016/08/Willis-conf2015-slide6_management-methods.png)
In the paper, he talks about three models.
Divergent infrastructure is our classic, unmanaged architecture. We build a system when we want to build it, we build it any way we want. But we get no OPEX value out of that kind of model.
Convergence. Now this is the principle that Puppet and Chef are built on. With convergence we get scalable infrastructure that’s given us unbelievable results over the last five or six years.
How do you build scalable infrastructure with convergence? You build repeatable, buildable infrastructure through an abstraction that is constantly converging. Typically, you run something on an agent and maybe every 30 minutes or an hour, it’s synchronizing, converging back to a state. So, you’re always converging, diverging, converging, diverging.
In his paper, what Steve Traugott was talking about as the ultimate goal is congruence. A model that is congruent from day one and stays congruent.
We can assume that divergence is a bad model, so that leaves convergence. The question is: if you’re a convergent environment, what is the current‑at‑this‑moment state? What if you have to get to the state that you think you need to be at this moment?
There’s a SaaS‑based, multitenant, high‑frequency trading company out in New York that runs completely on containers. At five o’clock every day, they wipe the system clean and build it up. Now, some of you might find that hard to believe, but it’s happening and their customers include Goldman Sachs.
This is the Holy Grail, and this company’s figured out a way to build a bulletproof, congruent infrastructure with containers, to be able to actually allow companies like Goldman Sachs and a couple other large financial titans to actually use their SaaS for certain HFT infrastructure.
8:40 Why (When) Does Order Matter?
![The order of changes made on a host matters because you need to avoid circular dependencies and the problems that come from running the right command (or installing the right package) but in the wrong order [presentation by John Willis, Director of Ecosystem Development at Docker, at nginx.conf 2015]](https://cdn.wp.nginx.com/wp-content/uploads/2016/08/Willis-conf2015-slide7_why-matter.png)
The convergence model requires a level of abstraction for how you build infrastructure. You build infrastructure through some language, a recipe, a manifest, or some DSL‑based infrastructure.
Now, when you use abstraction, you need to be aware that the abstraction has some things that could bite you, especially at scale.
Does this matter at a hundred machines? Absolutely not. Does it matter at a thousand machines? Probably not. Ten thousand? Maybe. A hundred thousand? Yeah.
[When] you start getting into large‑scale enterprise infrastructure, it really matters, especially when you’re using more deterministic, procedural configuration management tools like Chef. At the time I worked at Chef, Puppet instead used a dependency graph. When I went out to people running Puppet at scale and explained this Order Matters concept, they totally understood. Because when you’re building 10,000 or 100,000 machines and the order of build steps is just a little different for even one machine, it matters. (Chef and Puppet now use practically the same model, so this isn’t an issue for Puppet anymore.)
You can run into issues like circular dependencies. For instance if you’re using some tool that uses an abstraction to build infrastructure, and you’re updating that product itself, and that product is updating the infrastructure, you could have a circular dependency.
When you look at a Chef recipe or a Puppet manifest, much of it is just commands in a certain order. It’s good because it’s all in source control; it’s repeatable. But in some cases you do five commands, then the sixth command silently dies, it doesn’t really break, then the seventh command works, and that may happen on only one system.
I was given the opportunity to see a report by JP Morgan Chase. They completely abstracted their infrastructure using one of these three tools (Chef, Puppet, and CFEngine), and they thought they had a good setup. They had desired‑state, converged infrastructure.
Then they decided to turn the knob up on how often they checked for divergence.
Usually, people are on a 30‑minute or hour period to always converge back. In this case, they just wanted to get more granular view, so they shortened their period to something ridiculously low, like 5 seconds or 3 seconds.
To their amazement, they found that over about a three-day period there were about a billion unplanned changes on their infrastructure per day.
If you’ve ever heard of the concept of the Butterfly Effect, you can picture the ramifications. So think about that playing out, where one thing goes haywire and you’re trying to troubleshoot that.
This is the core of the argument in Traugott’s paper. Right command, wrong order [or] right package, wrong order – you can end up with a mess.
In my opinion, after 35 years of IT operations experience, when it comes to scalable infrastructure, if I can get a congruent environment, I want one.
13:40 Package Example
![Slide depicting the bad consquences of not being able to rollback to a previous state when an update fails [presentation by John Willis, Director of Ecosystem Development at Docker, at nginx.conf 2015]](https://cdn.wp.nginx.com/wp-content/uploads/2016/08/Willis-conf2015-slide8_package-example.png)
Now, I’m not saying converged infrastructure or desired‑state configuration management is a bad thing. It’s been amazing for us in our industry.
But I want to say that when you’re using an abstraction – and this is what Steve Traugott’s paper tries to point out as well – there are some potential pitfalls.
Here is an example where I need to install an upgrade to OpenSSH. To put it in, I use a Puppet primitive called package with this parameter called ensure.
For whatever reason, that package fails or maybe I just need to do some form of rollback.
But when I try to roll back, it’s not smart enough to go, “Oh, I know what exact state you were at when we did this, so I’m going to go back and traverse and get you back to that state”.
The package primitive is not that sophisticated. It’s pretty dumb actually – it just gives you a rote slam‑in.
15:15 More Nightmares
![Slide describes problems resulting from not maintaining older versions of packages in case rollback is necessary [presentation by John Willis, Director of Ecosystem Development at Docker, at nginx.conf 2015]](https://cdn.wp.nginx.com/wp-content/uploads/2016/08/Willis-conf2015-slide9_nightmares.png)
Now the person tries to go ahead and get back to that state, but it’s not there. Oh and by the way, they can’t even find the package that was originally there.
This is an argument against bad hygiene for infrastructure, but I would say there are models today where this would not be a problem, and it is with immutable infrastructure.
18:00 Immutable Infrastructure Model
![A model for immutable infrastructure prescribes "no CRUD" (Create, Replace, Update, and Delete) for packages, configuration files, and software [presentation by John Willis, Director of Ecosystem Development at Docker, at nginx.conf 2015]](https://cdn.wp.nginx.com/wp-content/uploads/2016/08/Willis-conf2015-slide10_model.png)
So, the people who do immutable infrastructure right – in general, what do they do?
I spoke to a lot of companies that are doing this, and what I came up with was “No CRUD allowed” for infrastructure. That’s Create, Replace, Update, and Delete. In general, this is a methodology that people apply where they’re just not going to create anything new on a running infrastructure. Generally that’s production, but it could be a test environment that’s quasi‑production.
You’re not going to change your config files. You’re not going to update any configuration. You just replace and roll forward.
Now databases are always the tricky ones. I’d say it’s kind of “No RUD”. They actually do have to record. They’ll create a new one, they’ll kind of change the state of the old one to the new one; so here, try to keep those records forever, or as long as possible.
19:00 How to Do Immutable
![The way to do immutable infrastructure is to provision a new server, test it, switch clients to it from the old server, and keep the older server around for rollback [presentation by John Willis, Director of Ecosystem Development at Docker, at nginx.conf 2015]](https://cdn.wp.nginx.com/wp-content/uploads/2016/08/Willis-conf2015-slide11_how-to-do.png)
So, how do you do this? It’s pretty obvious, but you provision a new server and you test it.
A book I recommend on this topic is Continuous Delivery by Jez Humble. It’s a very thick book, but it’s the Bible on how to do continuous integration, continuous delivery.
In that book, he talks about blue‑green deploys. Let’s say you have a cluster, you basically pull one node off the cluster, you change the status, you change it green, you make the update, you put it back, then you grab the next one, and you do this again.
This is kind of a model for immutability. You’re always rolling forward, whether it’s a large cluster or it’s a single system.
So, you change the reference to the server and you keep the old server around for rollback.
As an analogy, I like to think of immutable objects in Java, because basically you just change the point of reference. That’s basically what I’m saying we’re doing here. We’re basically changing the point of reference to the server that we just swapped.
I would note that in general you don’t take legacy or a whole application and say, “Hey, I heard this guy at NGINX conference talking about immutable infrastructure. Let’s go change our stuff to that”. It’s usually greenfield architectures that you’re trying to build with immutable infrastructure.
21:45 The Immutable Trombone
![The IT industry has historically moved back and forth like a trombone slide on the importance of immutable delivery [presentation by John Willis, Director of Ecosystem Development at Docker, at nginx.conf 2015]](https://nginxblog-8de1046ff5a84f2c-endpoint.azureedge.net/blobnginxbloga72cde487e/wp-content/uploads/2016/08/Willis-conf2015-slide12_trombone.png)
As an industry, we’ve been going back and forth like a trombone slide on the idea of immutability.
There was a time in IT where every desktop was built with golden images. If you’re old enough, you may remember Ghost. How did that turn out? Okay, but not great.
The industry adapted and VDI was basically a reaction to some of that, how to basically do OPEX on infrastructure. Virtualization got really huge. That looked awesome, and to give credit where credit is due, the industry has benefited heavily from virtualization over the last 15 or 20 years.
But with virtualization, we ran into problems with image sprawl. If we don’t have good hygiene for those images, “Whoops, I started the wrong image, that was the development one”.
In 2012, Martin Fowler wrote a couple great articles on Phoenix servers versus Snowflake servers. He basically said, “What if I could go into a data center with a bat and smash up all the servers and magically build them right back to where they were?” And the Phoenix server concept is that out‑of‑the‑ashes kind of idea, which actually also coincides with the whole Infrastructure as Code movement. The idea is to start out with just enough operating system, and then incrementally build.
The beauty is that it’s repeatable. The negative is that it’s not immutable. How you built it on your laptop, how you built it in CI, how you built it in QA, how you built it in production, could all be different. So there are some pitfalls.
And this is essence of the whole Bake vs. Fry argument. Baking is booting an image that’s already fully configured to where you want, while frying is taking a base, a bare‑bones operating system, and then using a recipe and adding ingredients with configuration management until it gets to where we want.
The bake argument is really strong except if you don’t have good image hygiene, because bake is, turn it on, it’s up where it’s supposed to be. And I like that, that’s really clean.
I was fortunate to sit down with Adrian Cockcroft from Netflix in Los Gatos for a day. I got to see how they did infrastructure and they had good hygiene. So the immutable infrastructure model works really well if you’ve covered your bases.
In their world, and this was pre-Docker, before the whole container trend, they basically built the building of the image into the CI/CD process.
So, the source code for the AMI was in Git. They did a pull request, it went into integration, the output of that was an AMI image, that went into Nexus or one of those image repositories. At provision time you pulled the latest and greatest version.
And that’s how we do source code, right? So it’s treating infrastructure the same way we do code.
In fact, I would say that Infrastructure as Code is not really Infrastructure as Code. If you think about what we do with code, we compile the artifact, we put it in there, we pull all the binaries; we don’t compile it at runtime. Infrastructure as Code implementations are just‑in‑time compilers because we are really building it on the fly as we’re implementing.
And then we have containers. I will say in general, Docker adds some value beyond just the containers themselves; it adds some secret sauce. Docker is not just Linux containers. It’s also about how you deliver a container.
A property of containers in general is that they rely on the host: they share the host operating system. Because they’re processes, they don’t really have a hypervisor. They instantiate in 500 milliseconds as opposed to maybe 2 minutes, 3 minutes, whatever.
They don’t necessarily, as an operating model, rely on kind of a convergence of how to connect multiple services. They just build in and use service discovery.
So in general, people who work with containers in service‑oriented structures, like microservices, literally tend to build their infrastructure in about 2 or 3 seconds.
The other thing that Docker does well, is they borrowed some other things that aren’t just containers. They borrowed union file systems using a copy‑on‑write model.
So people who deliver immutable infrastructure with Docker will build their service infrastructure on their laptop – typically on one virtual box machine running, say, Vagrant. Maybe five or six services: one of the services they own, the four others they don’t own. They test that. If they have to retest, their rebasing of that complete service is a couple of seconds. There’s no 8‑minute, 15‑minute, 20‑minute context switches.
Then, they deliver that to the CI process as immutable binary artifacts. If that goes green through that process, they get delivered on to production as immutable binary infrastructures, and basically bit‑for‑bit you have a congruent infrastructure, and I call it immutable delivery, not immutable infrastructure.
29:27 Case Studies
![In a case study presented at DockerCon14, Michael Bryzek discussed immutable infrastructure [presentation by John Willis, Director of Ecosystem Development at Docker, at nginx.conf 2015]](https://cdn.wp.nginx.com/wp-content/uploads/2016/08/Willis-conf2015-slide13_case-studies.png)
At DockerCon 2014, Michael Bryzek gave a presentation about immutable infrastructure. At around 28:04 he made a great point.
He said that nowadays, with our infrastructure, when our developers check in their code, it’s four or five binary artifacts with one metafile and that goes to the system.
Before that, our infrastructure was a wasteland of thousands and thousands of release engineering scripts that were built by people in all parts of the organization. Some of those people could even be gone from the organization.
References and Recommended Reading
Docker and the Three Ways of DevOps
Trash Your Servers and Burn Your Code: Immutable Infrastructure and Disposable Components
Building with Legos
Why You Should Build an Immutable Infrastructure
Baked Servers vs Fried Servers
Why Order Matters: Turing Equivalence in Automated Systems Administration
Deploying NGINX and NGINX Plus with Docker